Machine translation requires vast amounts of data to be effective. At a minimum, 4-5 million strings of data are needed to build a successful machine translation engine, although some professionals recommend at least 100 million strings.
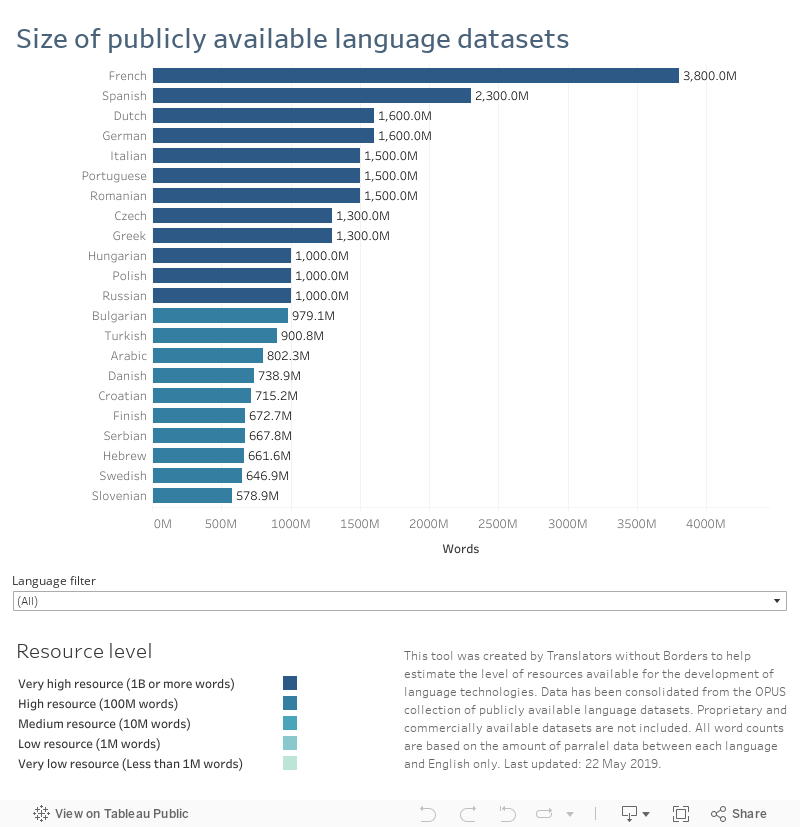
Yet despite the rapid development of language technology for languages like French, Spanish, and German, languages of people living in parts of the world with less commercial power are being left behind. Unless we do something, this digital language gap will only continue to grow.
That’s why we’re using Gamayun, the language equality initiative, to build language data sets and create scalable, replicable machine translation engines.
The table below demonstrates the current availability of language data that can be used to develop language technology. The volume of data does not always correspond to the number of speakers. For example, there are 23 million Dutch speakers worldwide, and 1.6 billion strings of Dutch language data. Meanwhile, there are 63 million speakers of Hausa globally, but only 3.1 million strings of data.
This needs to change—everyone deserves the right to communicate in their own language.
Help us bridge the language data and technology gap: contact Grace Tang, Gamayun Program Manager, at grace@translatorswithoutborders.org.