Cartes et données linguistiques
L’initiative pour les données linguistiques de CLEAR Global met en lumière le rôle clé des langues dans le secteur de l’humanitaire et du développement.
On dispose de peu d’informations sont disponibles sur les langues parlées et comprises par les personnes touchées par une crise. Les organisations humanitaires élaborent souvent des stratégies de communication sans disposer de données fiables sur l’alphabétisation, les langues parlées ou les moyens de communication préférés. Il en résulte trop souvent que les personnes touchées par une crise ont du mal à communiquer avec les organisations humanitaires dans une langue qu’elles comprennent. Les femmes, les enfants, les personnes âgées et les personnes handicapées sont souvent les plus désavantagés car ils sont moins susceptibles de comprendre les langues internationales et les langues véhiculaires.
Nous aidons les organisations à mettre en place des stratégies et programmes de communication adaptés au niveau linguistique grâce à nos travaux de recherche et d’analyse des données linguistiques.
Données par pays
Identifiez les langues parlées dans chaque pays grâce à nos cartes et données.
Questions sur les langues
Des questions préformatées et traduites pour vous aider à recueillir des données linguistiques.
Vos contributions et commentaires nous aideront à assurer l’accessibilité et l’utilité des données linguistiques.
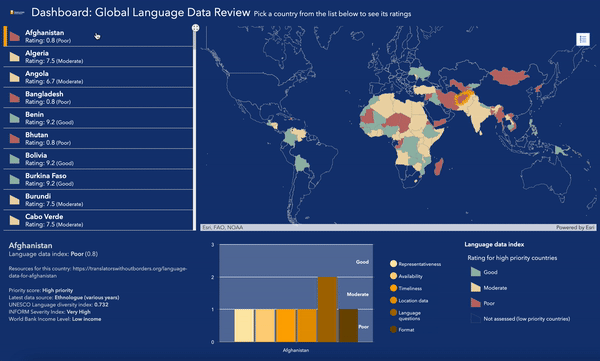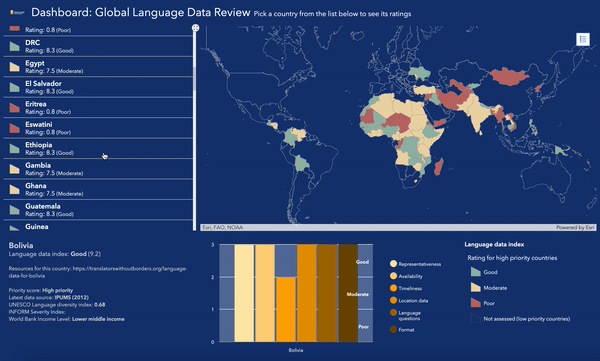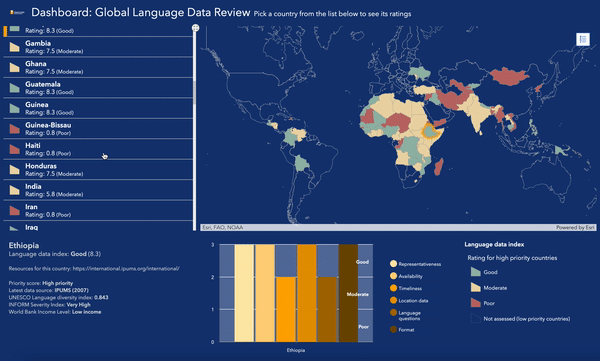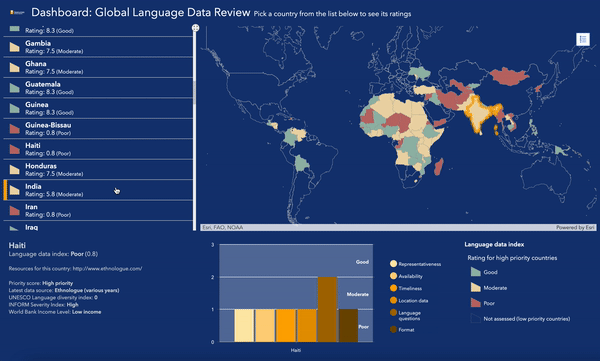
Pour en savoir plus sur l’état des données linguistiques dans le monde, consultez la carte évolutive et le tableau de bord de notre Examen des données linguistiques mondiales.
Outils et ressources
Cinq étapes simples pour intégrer les données linguistiques aux programmes humanitaires et de développement
Pour répondre aux besoins des populations touchées par les crises, les données concernant les langues qu’elles parlent et comprennent ont autant d’importance que les données concernant leur âge et leur genre. Ce guide de référence vous aidera à identifier rapidement les données linguistiques à utiliser pendant les différentes phases de planification et de mise en œuvre des programmes d’aide.
Note de synthèse : Les évaluations multisectorielles des besoins (MSNA) de 2021 doivent permettre la collecte de données sur les langues des populations touchées
Consultez la Note de synthèse disponible en anglais et en français.
Cette note de synthèse souligne que les évaluations multisectorielles des besoins sont essentielles pour élaborer des plans d’intervention humanitaire efficaces et redevables sur la base de données probantes. Elle propose des questions sur les besoins linguistiques et les préférences de communication des populations, ainsi que des pistes pour les inclure dans les évaluations multisectorielles.
Blog : Les données linguistiques permettent aux acteurs humanitaires de combler une lacune majeure
Ce blog rappelle les efforts déployés pour permettre aux acteurs humanitaires de neuf pays d’accéder à des données linguistiques. Les ensembles de données disponibles sont le résultat d’un partenariat entre Translators without Borders et l’University College London.
Carte représentant le niveau d’alphabétisation par genre
Cette carte met en évidence les différences en matière d’alphabétisation entre les hommes et les femmes par pays. Le taux d’alphabétisation des femmes est souvent plus bas que celui des hommes. Les pays en orange présentent un taux d’alphabétisation des hommes supérieur à celui des femmes. Les pays en bleu, plus rares, présentent un taux d’alphabétisation des femmes supérieur à celui des hommes.
Pourquoi est-il essentiel de recueillir des données sur les langues parlées par les personnes touchées par une crise (PDF)
Ce document infographique met en lumière les défis qui se posent lorsque le processus de prise de décision humanitaire ne prend pas en compte les données linguistiques. Pour relever ces défis, nous proposons d’inclure quatre questions aux efforts de collecte des données humanitaires.
Document disponible en anglais, en swahili, en français et en lingala (facile).
Les données linguistiques des évaluations multisectorielles des besoins peuvent aider les acteurs humanitaires à mieux communiquer avec les populations touchées par les crises (PDF)
Cette note de synthèse résume les enseignements tirés de l’évaluation multisectorielle des besoins réalisée en 2019 dans la région nord-est du Nigeria en matière de langue et de communication. Elle montre que ce type d’évaluations à grande échelle peut jouer un rôle crucial pour combler des lacunes majeures en matière de données linguistiques et de communication dans le secteur humanitaire.
Blog : Quand les mots font défaut : utilisation des enregistrements audio pour la vérification dans le cadre d’enquêtes multilingues
Ce blog s’intéresse à la possible utilisation de méthodes audio pour confirmer le consentement des personnes et vérifier l’exactitude des résultats des enquêtes dans des environnements multilingues. Il se concentre sur un projet pilote mené conjointement par Translators without Borders et l’Observatoire des situations de déplacement interne.
Guide de localisation et de traduction des outils d’enquêtes
Ce petit guide permet aux agences humanitaires et de développement d’éviter les préjugés linguistiques et culturels lors de la création et de la conduite d’enquêtes. Ce guide a été développé par Translators without Borders et People in Need. Il est disponible sur le site Web d’IndiKit en anglais, en français et en portugais.
Les mots qui nous séparent : Les agents recenseurs comprennent-ils la terminologie utilisée dans les enquêtes humanitaires ?
Ce rapport montre que les langues ne sont généralement pas prises en compte pendant le processus de conception des enquêtes, et conclut que souvent, les agents recenseurs ne comprennent pas les termes qu’ils doivent traduire.
Placer les langues au cœur de l’action européenne en faveur des réfugiés
Ce rapport met en lumière les défis posés par l’absence de données linguistiques fiables dans les contextes de crise humanitaire. Il s’intéresse notamment aux évaluations menées en Grèce, en Italie et en Turquie, et propose une série de recommandations qui a par la suite donné naissance à l’Initiative pour les données linguistiques de TWB.