Despite substantial increases in investment and research efforts in African language AI, the state of technology for African languages still lags behind major languages like English, French, or Mandarin (Adebara et al. 2025), as well as languages of other Global South regions like India. In this article, we present the results and key learnings from a series of interventions delivered as part of a Gates Foundation-funded project from September 2024-March 2026 designed to support the further advancement of African NLP and language AI. We will use the expressions “natural language processing”, or NLP, and “language AI” interchangeably. This work has covered three primary areas: benchmarks and evaluation, evidence toward data scaling laws, and synthetic data.
Many recent initiatives have focused on data creation, which remains one of the principal bottlenecks to improving African language AI. While these investments in data have contributed to improvements in performance, data alone is insufficient. Evaluation is also required to better understand the current state of African language AI. Such understanding will be pivotal to guide future investments and efforts, especially for languages that have so far received insufficient resources.
Beyond evaluation, future progress will also depend on understanding what levels and types of investment are required to achieve meaningful improvements in model performance. Research on scaling laws for major languages has advanced substantially in recent years (Kaplan et al. 2020, Hoffmann et al. 2022), providing clearer evidence on the relationship between data and performance. For low-resource languages, however, this area remains comparatively underexplored, leaving significant gaps in evidence-based planning and investment strategies.
Finally, our findings from investigating data scaling laws, combined with the realities of currently available resources, suggest that existing datasets and present investment levels are unlikely to be sufficient to adequately support the majority of Africa’s estimated more than 2,300 languages and the world’s over 7,000 languages (as reported by sources such as UNESCO or Ethnologue). This constraint motivated us to explore synthetic data generation as a potential complement to traditional human-centered data collection approaches.
The African NLP and language AI landscape in early 2026
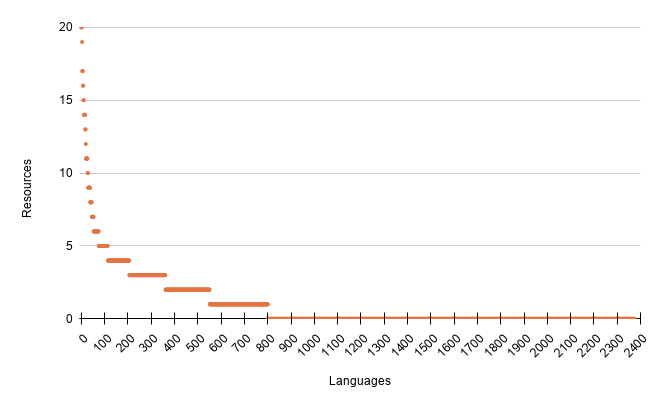
African Natural Language Processing and language AI have progressed substantially in the last five years. An analysis by Alabi et al.’s (2025) of over 800 publications from 2019 to 2024 showed the growing focus on African languages within NLP research, with the majority of the publications being published in 2023 and 2024, alongside a broader increase in attention to low-resource languages (Joshi et al. 2020). Alabi et al. also report skewed coverage of the over 2,300 languages spoken across the African continent, with the 20 most-studied languages accounting for a major share of all publications. In terms of language families, the Atlantic-Congo family (including Bantu languages such as Swahili, Kinyarwanda, Lingala, and Zulu), Afro-Asiatic family (which includes Arabic, Hausa, and Amharic), and Indo-European family (crucially Afrikaans) dominate the languages covered.
Beyond these overviews, there are also studies that looked at specific countries (Grover et al. 2010 on South Africa, Tonja et al. 2023 on Ethiopia, Amol et al. 2024 on Kenya, Nwafor and Andy 2022, Inuwa-Dutse 2025 on Nigeria, Azunre et al., 2021 and Issaka et al. 2024 on Ghana) or languages (Sibeko and Setaka 2022 on Sesotho, Jimoh et al. 2025 on Yorùbá).
As attention to low-resource languages has grown, so too has the need for more precise definitions of what “low-resourcedness” actually entails (Nigatue et al. 2024).Increasing investment has led to the creation of substantial resources for a limited subset of languages, making distinctions among low-resource languages themselves increasingly important. Data-driven categorization frameworks, such as those proposed by Joshi et al. 2020 and more recently by Zamir et al. 2026, help to clarify this landscape. Nigatue et al. 2024 propose a more detailed analysis that takes different dimensions of low-resourcedness into account. From their analysis of 150 papers on low-resource languages, they derive socio-political aspects, resources, and artifacts as hierarchical factors, alongside agency as an overarching factor.
These advances have been supported by significant investments and collaborative initiatives, such as Mozilla’s Common Voice, the Lacuna Fund, the African Next Voices project, and the recently launched Masakhane AI Hub, among many other targeted efforts.
This progress is visible across the whole language technology stack. In machine translation (MT), for example, large multilingual MT models like NLLB (NLLB Team 2022) and Seamless4MT (Seamless Communication et al. 2023) now include an increasing number of African languages.
Overview: What did we achieve?
Over the course of this project, we and our partners have published a range of materials providing more detailed insights into the individual interventions and their findings. As such, this section primarily aims to provide an overview of the different projects, their key outcomes, and where additional information can be found. We also summarize selected as-yet unpublished results and synthesize the broader learnings emerging across the portfolio of projects.
Evaluation, benchmarks and leaderboards
The team led by Prof. Muhammad Abdul-Mageed at the University of British Columbia created new and comprehensive datasets for text, the Sahara benchmark, and voice, the Simba Benchmark. They also improve language identification for African languages, including larger dataset and a refined language ID model. Their work has been published and the evaluation results are available in dedicated Hugging Face spaces:
- Sahara: A Comprehensive Benchmark for African NLP
- ACL 2025 Paper: Where Are We? Evaluating LLM Performance on African Languages (Adebara et al. 2025)
- Official Website and Leaderboard
- SimbaBench: Mapping Africa’s Speech Technology
- EMNLP 2025 Paper: Voice of a Continent: Mapping Africa’s Speech Technology Frontier (Elmadany et al. 2025)
- Official Website and Leaderboard
- AfroScope Framework:
- Paper: AfroScope: A Framework for Studying the Linguistic Landscape of Africa (Kwon et al. 2026)
- AfroScope-Data and AfroScope-Model on Huggingface
Beyond UBC’s work, we worked with various other partners to support and create additional evaluations:
- Workshop on Machine Translation (WMT): We supported the creation of training and evaluation data and human evaluation for the WMT25 General Machine Translation Shared Task
- Preliminary findings: Findings of the WMT25 General Machine Translation Shared Task: Time to Stop Evaluating on Easy Test Sets (Kocmi et al. 2025)
- Preliminary Ranking of WMT25 General Machine Translation Systems (Kocmi et al. 2025)
- Papers by the participants are available here
- Collected resources here on Github
- This work has already sparked follow-up analysis, like this meta-analysis here
- Kenya Clinical Reasoning Challenge: We supported the Kenya Clinical Reasoning Challenge hosted on Zindi in cooperation with PATH. In this challenge, participants were asked to predict clinicians’ response to various medical scenarios and thereby replicate the reasoning of trained professionals. Out of over 8,000 submitted solutions, the best one by Team Rocky AI from Canada achieved a Rouge-F score of 0.442. Further resources and details are available upon request.
- LLM Evaluation for Agriculture: In cooperation with Gooey, we created LLM evaluation datasets for agriculture in Kikuyu, Kinyarwanda, Swahili, Hausa, Fulfulde, Nigerian Pidgin, Yoruba, Igbo, Urdu, Pashto, Sindhi, and Punjabi.
Data scaling
Some of the results of the work on ASR data scaling for African languages are not yet published, and we provide details on the work of Sunbird.ai, the team of Dr. Joyce Nabende at Makerere University, and Badr Abdullah at Saarland University below.
Some components of their work have already been published and are available for further reference:
- Sunbird.ai:
A publication from Makerere University summarizing the results and findings of their work is forthcoming.
Synthetic data
Our work on synthetic data comprised two complementary components. The first, the SynVoices project, was led by CLEAR Global and Dimagi and focused on generating synthetic voice data to support African automatic speech recognition (ASR) systems. The second, the SynMT project, conducted by XRI Global, explored the use of grammatical and other linguistic resources to improve machine translation models. Detailed methodologies and results are available below:
- SynVoices:
- RANLP Paper: Synthetic Voice Data for Automatic Speech Recognition in African Languages (DeRenzi et al. 2025)
- Data and models can be found on CLEAR Global’s Huggingface space
- SynMT
- Paper: Testing the Limits of Machine Translation from One Book (Shaw et al. 2025)
- Data and models can be found on XRI Global’s Huggingface space
Martin Benjamin led a complementary project to support the SynMT work through targeted language selection based on the identification of existing grammars and dictionaries, as well as conducting a broader systematic mapping of African languages and their NLP-relevant resources, with a focus on grammars and dictionaries. This resulted in the creation of an open-access African language grid as a central database of languages and available resources, alongside linked language-specific resource pages. These were developed with contributions from over 200 stakeholders and are intended to support ongoing discovery and community contribution of linguistic resources.
Data points towards Automatic Speech Recognition data scaling “laws” for African languages
As some of the data generated through our work on data scaling for African Automatic Speech Recognition (ASR) has not yet been published, this article also serves as an opportunity to share those data points and insights. We further combine them with the already published findings from Sunbird.ai.
Motivation
Substantial efforts are currently underway to create missing voice data sets for African languages. These efforts are informed by past experiences, often anecdotal, but rarely guided by systematic information about how much data is needed, for which languages, and in which contexts. At the same time, each new proposal, project, and partnership must allocate scarce resources across multiple languages, domains, and data collection approaches when designing projects.
This work aims to help close this gap by providing additional data points on the relation between dataset size and performance—often referred to as data scaling laws (analogous to compute scaling laws). These ‘laws’ describe the relationship between increasing one input (here, data) and performance gains. While data scaling laws are well explored for majority languages (Kaplan et al. 2020, Hoffmann et al. 2022), they are largely absent for low-resource languages.
Creating robust data scaling laws is beyond the scope of this work. However, we hope to contribute additional data points that can provide first indications for partners collecting data or developing models.
Through the combined effort of our partners, we gathered various data points on the relationship between training data size and ASR performance. Both Sunbird.ai and Badr Abdullah from the University of Saarland trained ASR models for Kinyarwanda, but with Wav2Vec-Bert-2.0 and Whisper large v3 used different model architecture which allows us to compare their increase in performance at different training dataset sizes. Sunbird.ai’s results have since been published in pre-print.
Sunbird.ai trained Whisper large v3, a 1.55 billion parameter model that has shown promising performance in previous work on East African languages due to its ability to produce transcripts with correct punctuation and capitalization (the models are available here). Whisper large v3 also allows for text prompts to provide the model with information about context or specialized vocabulary. Whisper large v3 requires about 8GB of VRAM to run. On a RTX4090 GPU, which retails at around 1,600 USD, Sunbird achieved a real-time factor of 0.15, i.e. transcribing 1 minute of audio takes approximately 9 seconds (or 1 second approximately 150 milliseconds), but note that this could be further optimized.
They adapted hyperparameters and data augmentation from their successful Kaggle submission (hyperparameters: learning rate 1e-5, batch size 32, early stopping if no improvement on validation is seen within 4000 steps). They also added noise to the training data, augmented speed and downsampled 5% of the data to 8Khz to simulate phone speech. They used 3 H100 GPUs and A100 GPUs (for the lower training dataset sizes) for their model training.
Badr Abdullah trained a Wav2Vec2-BERT 2.0 with 600m parameters with up to 1000 hours from the same Kaggle competition (the models are available here).
Both used the same dataset provided by Digital Umuganda for the Kaggle competition. It included approximately 263,000 audio records across 5 domains: Health, Government, Financial Services, Education, and Agriculture. Each sample includes a single speaker with mostly clear audio and no background noise lasting 20 to 30 seconds. The speech is natural rather than prompted, resulting in a great diversity in speaker cadence. Sunbird.ai removed 7,000 mislabelled examples from the training data.
Results
Across the work of Sunbird.ai and Badr Abdullah, we have the benefit of comparing results across two different model architectures for Kinyarwanda, albeit with the training data amounts differing slightly.
The results are shown in Figure 2.
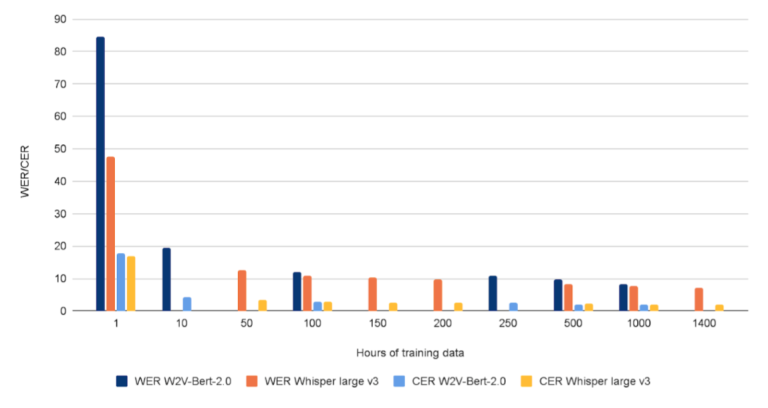
For larger amounts of training data, the results are similar, although Whisper large v3 shows reliably better performance and more efficient utilization of the training data than Wav2Vec-Bert-2.0. This is especially stark when training with only a very small amount of data (e.g. 1h). This could be due to differences in the pre-training, although this hypothesis would require further investigation.
In the case of Whisper large v3, we require 200 hours to achieve a word error rate (WER) below 10 (9.82 WER), although 100 hours already achieves a WER of 10.9, demonstrating the low marginal returns of training data beyond this point. Wav2Vec-Bert-2.0 required 500 hours to reach WER below 10 (9.6 WER) and reached 10.91 at 250 hours.
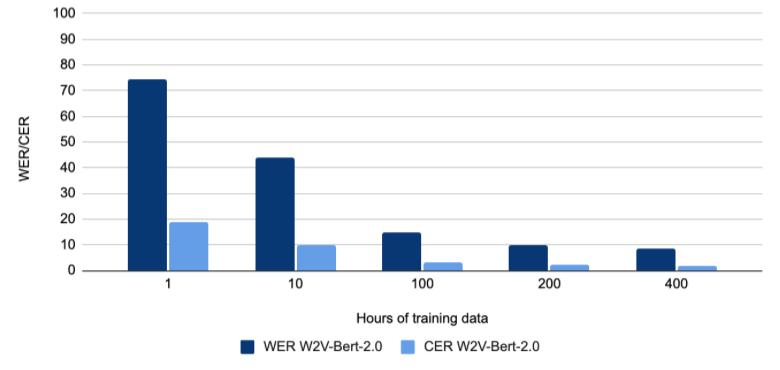
Through the work of Badr Abdullah, we can compare these results to training Wav2Vec-Bert-2.0 for Swahili. Those results are shown in Figure 3. Wav2Vec-Bert-2.0 shows more efficient training for Swahili, reaching below 10 WER with just 200 hours (9.69 WER) but improving just another point WER to 8.76 when adding another 200 hours of training data.
The results above do not account for data quality, which is usually more difficult to quantify. Badr Abdullah’s work on Kikuyu provides some insights into these challenges; he trained a Wav2Vec Bert 2.0 model on roughly 140 hours of transcribed Kikuyu. In contrast to Kinyarwanda and Swahili, this model did not or only very slowly converge, i.e. accuracy increased only slowly or not at all with additional training data. The most likely culprit is poor data quality and initial investigations of the the training data support this hypothesis: inspected data samples contain missing text transcriptions (audio with no text), inconsistent text encoding (e.g., for characters like ũ or ĩ which can be encoded as either one or two Unicode characters), and undocumented tags embedded in text transcriptions (e.g., [cs] and [pause]). It is likely that the remaining data also contains misaligned samples (non-corresponding speech and text), partially transcribed speech, and speech with a low signal-to-noise ratio. As a result, the lowest WER achieved on Kikuyu was 25.15% (the model is available here).
Further work on Fulani and Zulu indicates similar challenges. The 120h of transcribed Fulani data contains substantial amounts of noise, resulting in a best WER of 57 with Wav2Vec-Bert-2.0 and 40 with MMS with a similar learning curve as the Kikuyu model, demonstrating the effect which noise levels have on the utility of data. The 250 hours of usable Zulu data was of better quality and the learning curve therefore was smoother, without the erratic changes common with noisy datasets. The best Wav2Vec model achieved a WER of 16.27, higher than the Swahili and Kinyarwanda models with similar training dataset sizes (the model is available here). This is, however, probably still a good result considering the complexity of Zulu phonology compared to the other Bantu languages. These features contribute to the difficulty of ASR modeling for Zulu which appears as a higher WER and showcases that additional work is needed to create robust cross-lingual data scaling laws for African ASR. Additional work on Somali, Malagasy, and Shona supports those results.
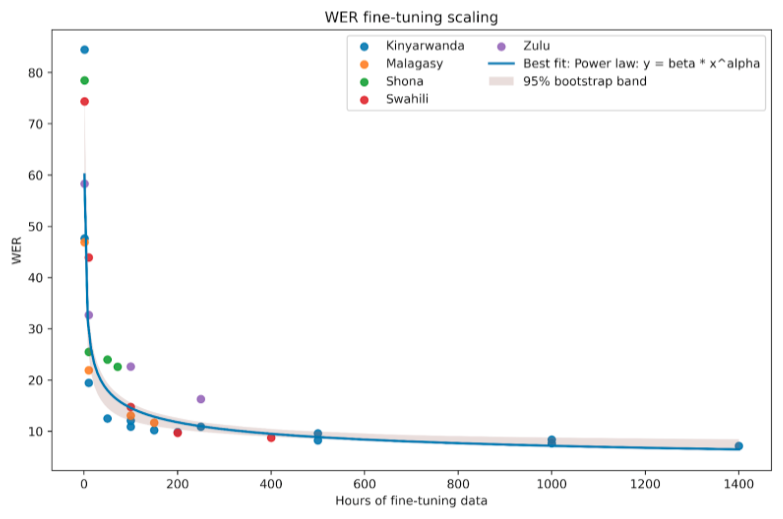
Combining the data from these activities allows us to illustrate what a data scaling law for African ASR might look like. However, this will necessarily be not yet robust given the small sample size and large underlying diversity of languages. The results for WER are illustrated in Figure 4. The figure shows a scatterplot of all data available as well as an estimated scaling law based on this data.
The estimated power law implies that each duplication of training data size reduces WER by 19.2%, at least for the studied languages and models. But we have to stress again that this is for illustrative purposes only. Developing more robust scaling insights will require additional data covering more languages, models, and data characteristics.
Learnings
On Benchmarks
Data availability
Language policy, data availability, and model performance are deeply intertwined. Environments that prioritize colonial or foreign languages often generate sparse, fragmented datasets, which predictably lead to weaker model outcomes. It is therefore essential to target policy alongside other interventions. Benchmark designers and funders should communicate their findings with the explicit aim of informing local language-relevant policy discussions, including in education and cultural policy.
The distribution of language resources is profoundly heavy-tailed: a few high-resource languages dominate, while the vast majority are severely underrepresented or entirely absent. Addressing this imbalance requires deliberate long-tail strategies—e.g. targeted data collection and research efforts and community-driven collection kits—rather than simply scaling what already exists. This must go hand in hand with attention to licensing and engagement with the speaker communities. Many datasets contain culturally sensitive content or ambiguous reuse terms; engaging local partners ensures that data collection and labeling respect both legal frameworks and cultural norms.
Benchmark design
Equally critical is the recognition that language technology benchmarks are living systems, not static PDFs. Rapid model iteration, prompt sensitivity, and evolving task definitions make traditional one-off leaderboards obsolete. To keep evaluations interpretable across time and models, the field must invest in robust operational infrastructure—versioning, metadata management, submission schemas, and audit logs. This operational backbone maintains the integrity of scores and prevents “benchmark drift” as models and data evolve. Sustainability here also means budgeting for ongoing maintenance, dataset hygiene, and training regional contributors to keep systems current and locally owned.
Technical infrastructure and preprocessing choices also shape fairness and performance. Speech pipelines, for instance, may appear standardized (e.g., 16 kHz mono, 1–20 s segmentation, VAD + diarization), yet optimal parameters differ across corpora—broadcast versus conversational, tonal versus non-tonal languages. Transparent parameterization and per-corpus tuning, combined with stratified quality assurance, are vital. Similarly, orthographic variation, multiple scripts, and code-switching expose weaknesses in tokenization and normalization. Instead of applying uniform text processing rules, developers should favor light, language-specific normalization and script-aware tokenization. Since code-switching is the norm rather than the exception in African text and speech, benchmarks should incorporate code-switched data, adopt code-switch-sensitive metrics, and avoid filtering these examples out as noise.
A reliable language identification (LID) layer is a keystone of all multilingual pipelines. Beyond its utility for routing inputs to the correct tokenizers or models, LID enables systematic error analysis and dashboarding across languages. Coupling LID with downstream tasks helps reveal coverage gaps and highlights where low-resource languages are underserved. However, any such infrastructure must be built on transparent data foundations. Contamination and leakage, where benchmark data reappear in model pretraining corpora, can distort evaluation results. Deduplication, provenance tagging, and hidden test splits are necessary safeguards, and limitations should be reported candidly rather than hidden behind inflated scores.
Finally, true measurement equity demands nuanced reporting. Aggregate metrics and macro averages can mask deep disparities between languages and families. Per-language and per-family results, complemented by confidence intervals, make these inequities visible. Explicitly flagging low-data regimes prevents over-interpretation of small test sets.
Together, these guardrails, which include policy awareness, operational rigor, transparent pipelines, ethical governance, and equitable measurement, form a coherent framework for building sustainable, trustworthy, and inclusive benchmarks in multilingual and low-resource contexts.
On Data Scaling Laws
The experiments suggest that model performance continues to improve with more data, but the relationship is far from uniform across languages and domains. The sheer linguistic diversity of the African continent—spanning phonetic inventories, tonal systems, differences in language use and orthographic conventions—means that scaling cannot simply be measured in hours of audio or number of utterances alone. Future scaling studies will need to explicitly incorporate diversity metrics, ensuring that additional data meaningfully expands linguistic coverage rather than over-representing already dominant languages or varieties.
Beyond quantity, data quality remains a critical determinant of performance gains. Preliminary results indicate that noisy or inconsistent transcriptions can plateau or even degrade model learning, suggesting diminishing returns beyond certain quality thresholds. Developing quantitative quality metrics—capturing aspects such as transcription consistency, signal-to-noise ratio, and linguistic fidelity—will be essential to model how quality and quantity interact. This will allow us to estimate performance improvements not only as a function of dataset size, but also of dataset quality.
Finally, future work must extend scaling investigations beyond clean, laboratory-style benchmarks to encompass partially relevant or in-the-wild data and downstream applications. Strong results on controlled datasets are only valuable insofar as they predict real-world performance in production environments, such as call centers, field recordings, or farmer advisory services. Understanding how scaling laws behave under these domain shifts will be central to building robust, context-appropriate ASR systems. In short, the next phase of scaling research must integrate linguistic diversity, data quality, and domain relevance into a unified empirical framework for African ASR.
On Synthetic Data
SynVoices: Key lessons learned
The key learnings from the SynVoices project was that synthetic voice data can complement human data, but only provides limited benefits. Especially for low-resource languages like Dholuo and Chichewa, where we would need synthetic data most, the benefits are limited to around 6% improvements which leave us with ASR models that do not show sufficient performance for practical application. At the same time, large language model (LLM) performance varies widely across languages and is often unpredictable. Human evaluation remains essential for determining the best-performing model per language.
However, this human evaluation in low-resource languages requires strict protocols and more reviewers. The project revealed that linguist identity sometimes had more impact on ratings than the model itself, affecting evaluation consistency.
While we always expected that existing LLMs would have a range of performance across various languages, extremely low-resource languages like Kanuri exposed that the model will sometimes output tokens for a language in a geographically similar area, even if there is limited linguistic overlap. In the case of Kanuri, some models would output Hausa sentences when prompted to produce Kanuri. These limitations emphasized the constraints of using existing LLMs in underrepresented linguistic contexts.
Contrary to our expectations, but based only on the available evaluation data, purely male synthetic data (a result of the available text-to-speech, or TTS, models) does not seem to deteriorate performance for women if combined with human data.
Lastly, the quality of the currently available evaluation data is in parts very poor. The data contains outright errors. In addition, we do not yet have a common way to reflect orthographic diversity in non-standardized languages.
SynMT: Key lessons learned
The most significant lesson learned was that grammar books, while valuable linguistic resources, are not optimally structured for AI systems to extract translation capabilities. Contrary to our initial hypothesis that comprehensive grammatical descriptions would provide superior results, we consistently found that parallel sentences extracted from those same grammars outperformed the full grammar approach across all languages and metrics. This suggests that current LLMs struggle to operationalize declarative linguistic knowledge effectively for translation tasks.
Another crucial insight was the discrepancy between automatic metrics and real-world usability, mirroring the learnings from the SynVocies project. The in-depth studies showed that ChrF scores, while being a good proxy of human evaluation at higher scores, are not indicative of translation performance at lower scores below 25. Human evaluations revealed stark differences between accuracy (meaning preservation) and fluency (naturalness). Translations often preserved core meaning, with 35% preference rate in humanitarian domains. This score was generated by comparing the AI translation with a human translation. The target for this score is therefore 50%, indicating that the human evaluators are indifferent between the AI and human translation, indicating equal quality. At the same time, they lacked natural expression (below 15% preference rate). This distinction was not captured by single-dimension metrics.
Key lessons learned from identifying dictionaries, grammars, and linguistic resources for African languages
CLEAR Global and XRI Global worked with Martin Benjamin to identify the required and additional linguistic resources that might help in advancing African NLP.
We found that substantial linguistic data exists only in print. Many high-quality dictionaries and grammars remain undigitized, limiting accessibility for NLP and AI. This includes historical print resources which often contain linguistically rich data that merits preservation and digitization. These resources are generally available through inter-library loan, often free of copyright restrictions, and have potential to be scanned and processed, but this would require more substantial resources to realize systematically.
At the same time, much available language documentation for African languages exists in digital form, but this does not imply that these resources are accessible for public use. Scanned PDFs of old dictionaries are often too inconsistent for machines to parse accurately, so the most reliable path to usable data is manual retyping by trained human eyes. Other resources sit behind paywalls, or are only accessible by purchasing at significant expense. An even modest shift in focus and investment toward prioritizing the collection and digitization of high-quality linguistic data at the core of technologies such as large language models would improve the prospects of African languages in emerging language technologies.
In the end, cataloguing the languages of Africa was a necessary secondary output to be able to work on the broad identification of resources. However, the catalogue, including the disambiguation of various names for languages, received great interest in the fora in which the linguistic work was presented. A natural next step from this work would be to develop the dataset further into a more user-friendly public-facing tool; while the resource is currently available as a Google Sheet resource and user guide, its reach could be increased through improved accessibility and usability. The same approach could also readily be extended to other under-documented regions, including minority languages in Asia, First Nation languages in the Americas, and Indigenous languages in Austronesia.
Conclusion
This project was a collaboration between a large number of partners from various domains and sectors. And this project showed how valuable such a collaboration can be if focused on the complementarities: whether our linguistic consultant Martin Benjamin’s support to XRI Global in identifying languages, CLEAR Global’s helping connect linguists to Makerere University for model evaluation, feedback that the projects provided to each other from academic and practitioner perspectives. While the practically oriented partners could provide use case experience pointing to necessary performance for practical application, UBC supported by connecting the discussions and projects to the wider academic work in the field.
The activities also demonstrate that experimentation is necessary. Not every approach was proved as promising as it appeared, but partial successes or unexpected challenges nonetheless generate valuable insights. At the same time, the work makes clear that simply repeating the same methods to advance African AI is insufficient. To achieve meaningful advancements, continued investment in experimentation to discover solutions tailored to the African continent’s linguistic diversity and practical contexts is key.
Across all projects, access to and partnership with native speakers was key. The evaluations in the SynVoices and SynMT projects as well as Makerere University’s work could not have been done without them, and the comparison of the insights gathered through them with automated metrics demonstrates that those metrics alone do not provide a comprehensive picture. Future projects therefore should plan from the beginning how to work with native speakers and consider where the effort of in-depth human evaluation is needed. Automated metrics have the benefit of ease of use and speed but as our work shows, their reliability for most low-resource languages is currently limited as data is missing or erroneous.
In the end, we believe that these projects show how much work still lies ahead of us, but also give a glimpse of the recent improvements as well as the importance of collaboration to further improve African language AI and integrate it into services and products that have a tangible positive impact on people’s livelihoods.
Acknowledgements
CLEAR Global is grateful for the support of the Gates Foundation that enabled this work and the sub-award and partnership with Dimagi, XRI Global, the University of British Columbia as well as various other partners. We are also grateful for the partnership with Sunbird.ai, Joyce Nabende, Alvin Nahabwe, and the team at Makerere University, Badr M. Abdullah, Martin Benjamin, Zindi, Toloka and the WMT, and Gooey.ai. We thank Howard Lakougna at the Gates Foundation, who provided trusted partnership and valuable feedback.
This work was supported by the Gates Foundation (Grant number INV-076358). The conclusions and opinions expressed in this work are those of the authors alone and shall not be attributed to the Foundation.