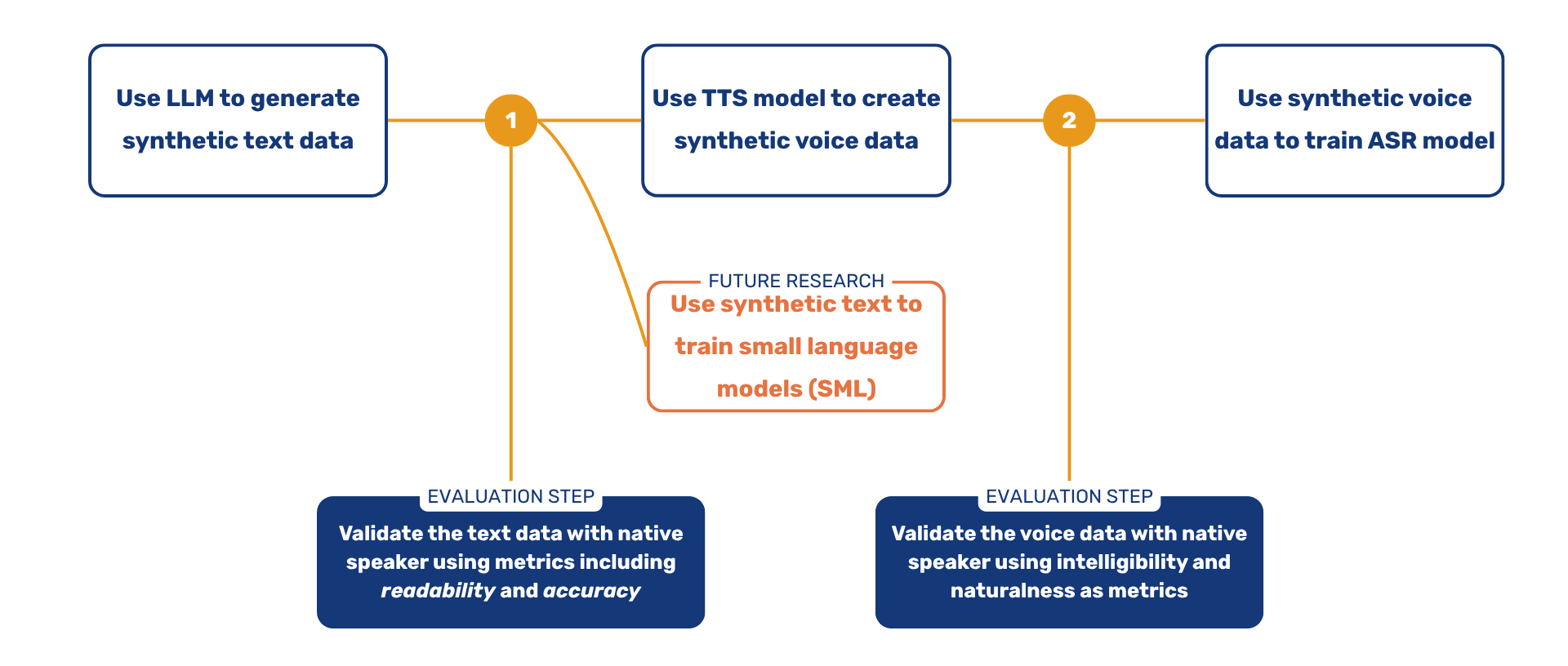
Overview of the process to create synthetic voice data
We describe the process step by step in the following sections. If you are mainly interested in the outcomes, skip ahead to the results section.
The first key result of this work is the evaluation of the quality of text generated by LLMs under step 1 of our process. The graph below compares mean readability scores on a seven-point scale across languages, including the results of smaller-scale generations and evaluation for Yemba and Ewondo. 8 out of 12 languages achieved mean rating above 5.0 which we took as the threshold to show sufficient quality for use to generate synthetic voice data under subsequent steps. The discrepancy between low-resource languages and very low-resource languages–here Kanuri, Kinande, Yemba, and Ewondo–is nonetheless stark. This was reinforced by evaluators for these languages who reported a range of issues including generation of sentences in an altogether different language; GPT-4o prompted to generate Kanuri sentences, for instance, was found to largely produce sentences in Hausa.
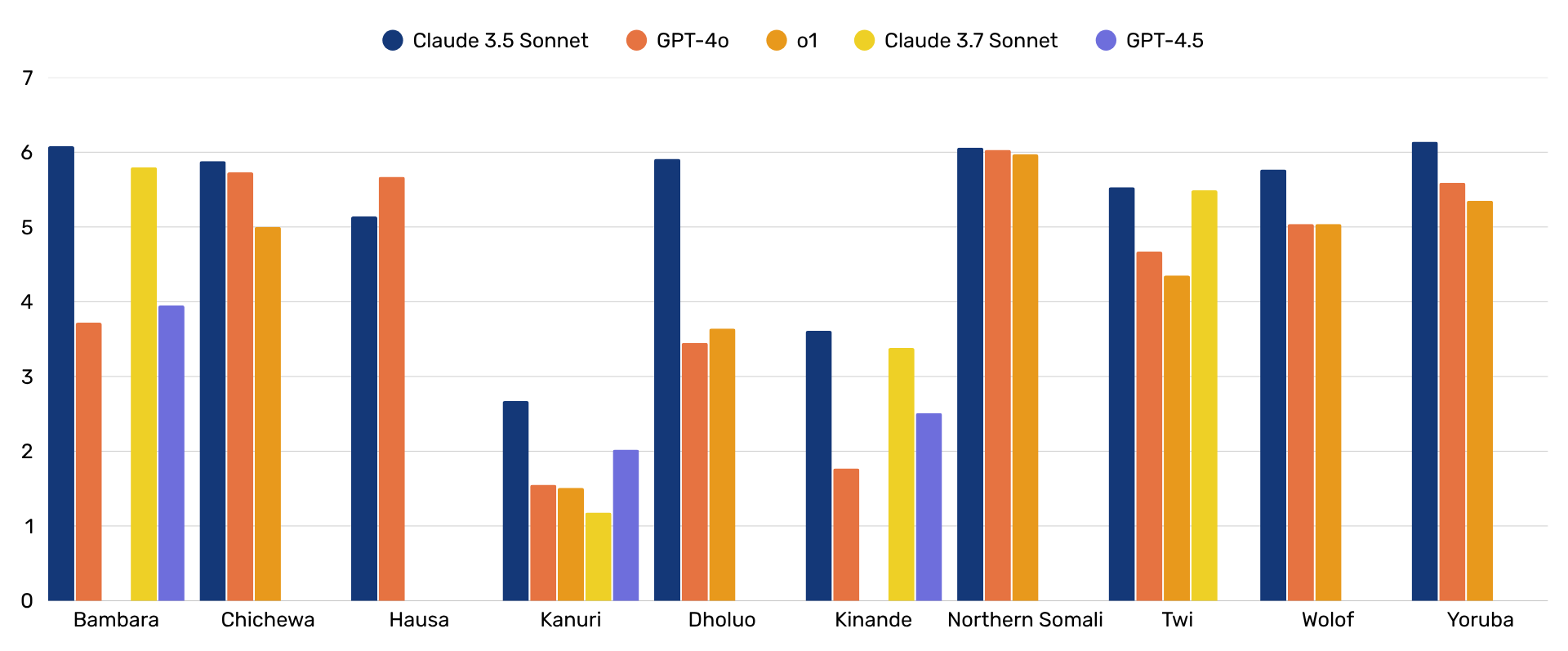
Comparison of readability [1..7] scores for synthetic text generated by various LLMs for 10 African languages
For Hausa, we kept the total amount of training data constant but varied the ratio between real and synthetic data. For this reason, we would expect to see similar performance, with the only difference that some of the training data is synthetic.
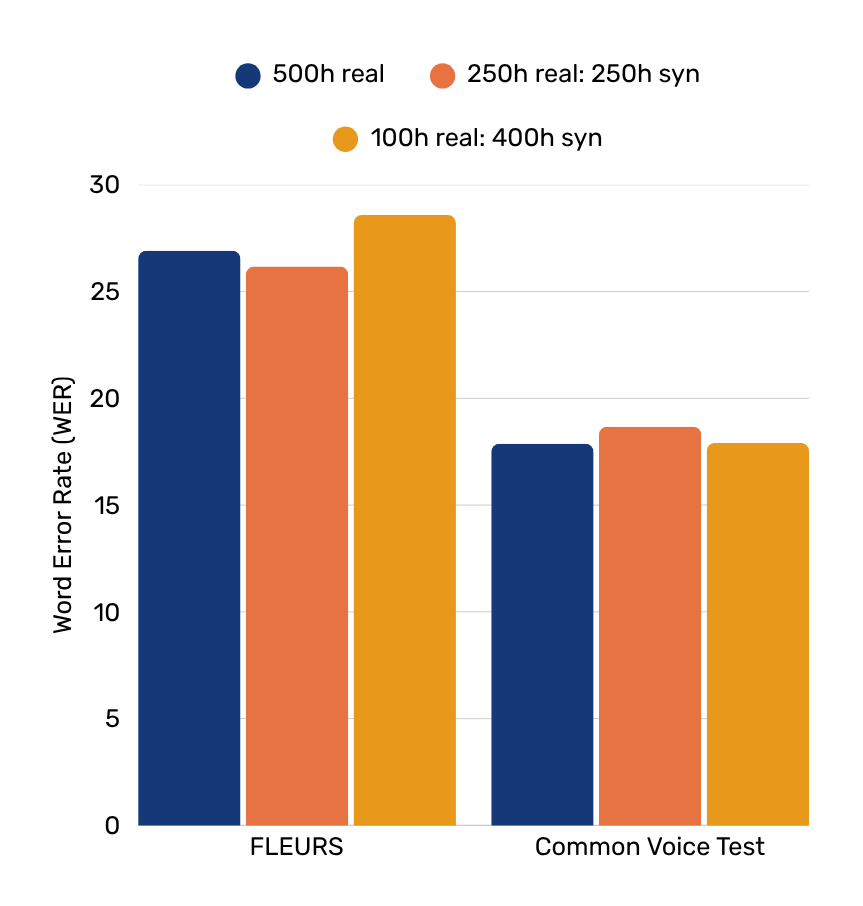 And this indeed is what we found: The results differ slightly depending on the evaluation set, but in general replacing half of the human data with synthetic data (i.e. 250h:250h) yields at worst only marginally worse performance than a model trained on 500h of real data. Evaluated with the CommonVoice evaluation data, the performance is even better. This also seems to stem indeed from adding synthetic data, as the improvement over the models trained on 100h and 250h of real data is similar.
And this indeed is what we found: The results differ slightly depending on the evaluation set, but in general replacing half of the human data with synthetic data (i.e. 250h:250h) yields at worst only marginally worse performance than a model trained on 500h of real data. Evaluated with the CommonVoice evaluation data, the performance is even better. This also seems to stem indeed from adding synthetic data, as the improvement over the models trained on 100h and 250h of real data is similar.
Given the synthetic voice data we generated was exclusively male (because there are only male speakers in the Bible corpus), we were concerned that the ASR models trained on the synthetic voice data would perform worse for women. With the CommonVoice and NaijaVoices dataset, we could evaluate this: On average, the fine-tuned ASR models in fact perform slightly worse for male than female voices.
Usually, models get better when trained on more data. And we found the same: Our best models were still those trained on all the data we had available, i.e. all human data and all synthetic data that we created, but the improvements are minor.
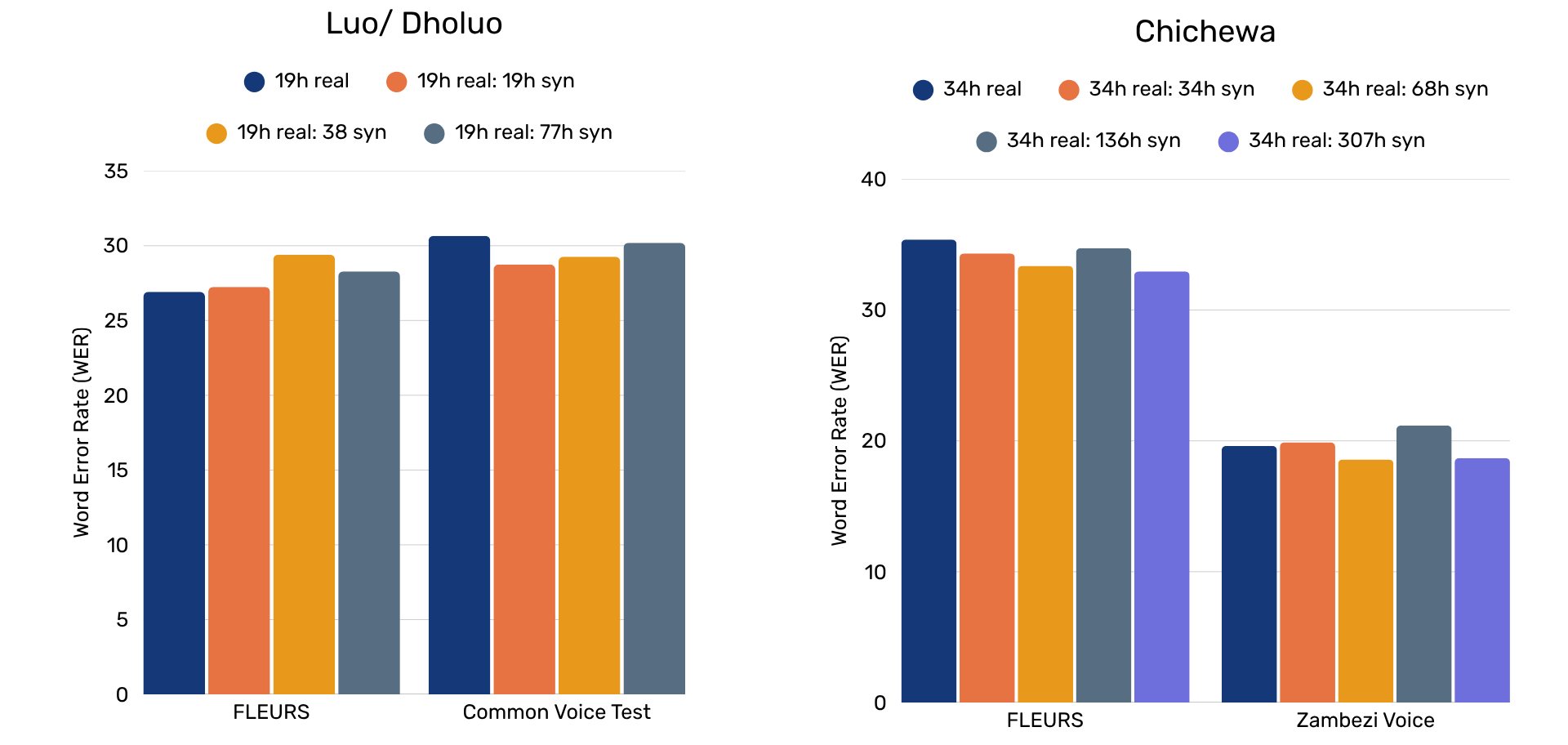
In the low-data scenario with Chichewa and Dholuo, we added ever more data to the training corpus and therefore would expect that performance improves as we add more data. In summary, this is unfortunately not what we found. There are minor improvements when adding the same amount of synthetic data as real data was available (i.e. 19 hours real: 19h synthetic and 34 hours real:34 hours synthetic), but there are no further improvements beyond this.
For Dholuo, they also depend on the evaluation data. When we evaluated with FLEURS, no amount of synthetic data yielded any improvement. When we evaluated with the CommonVoice evaluation data, the 1:1 ratio was around 6.5% better.
Chichewa showed some more promising results. A 1:1 ratio but also a 1:9 ratio resulted in some improvements of around 6.5%.